并行系统学习之路(四) ---- OpenMP学习
OpenMP 编程学习
本周的主题是Shared Memory Programming,也就是共享内存编程。首先,我们需要明确一下共享内存编程的基本概念。
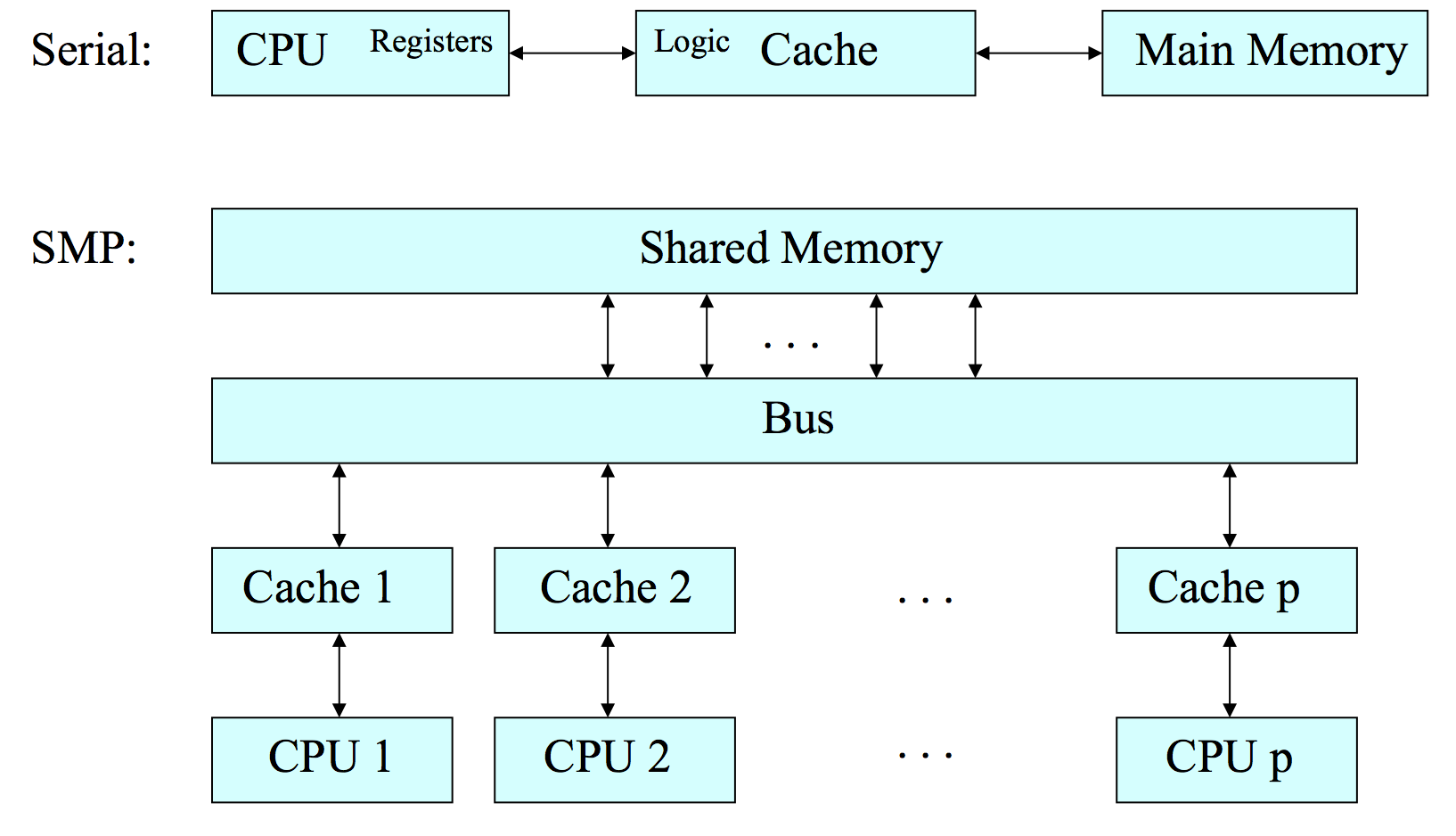
上图说明了单处理器和共享内存处理器的基本结构差异,我们可以看到共享内存处理器的最大特点就是CPU数量比单处理器多的多。很明显,利用这个特点,我们可以让一些特定程序运行的更快。这其实也是并行系统解决的基本问题。
共享内存编程的标准
-
使用线程库
- Win32 API
- POSIX线程库
-
编译器导向
- OpenMP(本篇重点)
-
信息传输库
- MPI
-
并行语言
- 存在许多语言但是没有任何一种是业界通用的
OpenMP介绍
- 编译器导向
- library routines
- 可以轻松编写多线程程序
- 支持Fortran, C, C++
- 面世20年,稳定
编程模型
- Fork-Join Parallelism:
- Master线程将根据需求产生多个子线程
- 由顺序执行的程序演变而来,并行化是可增加的
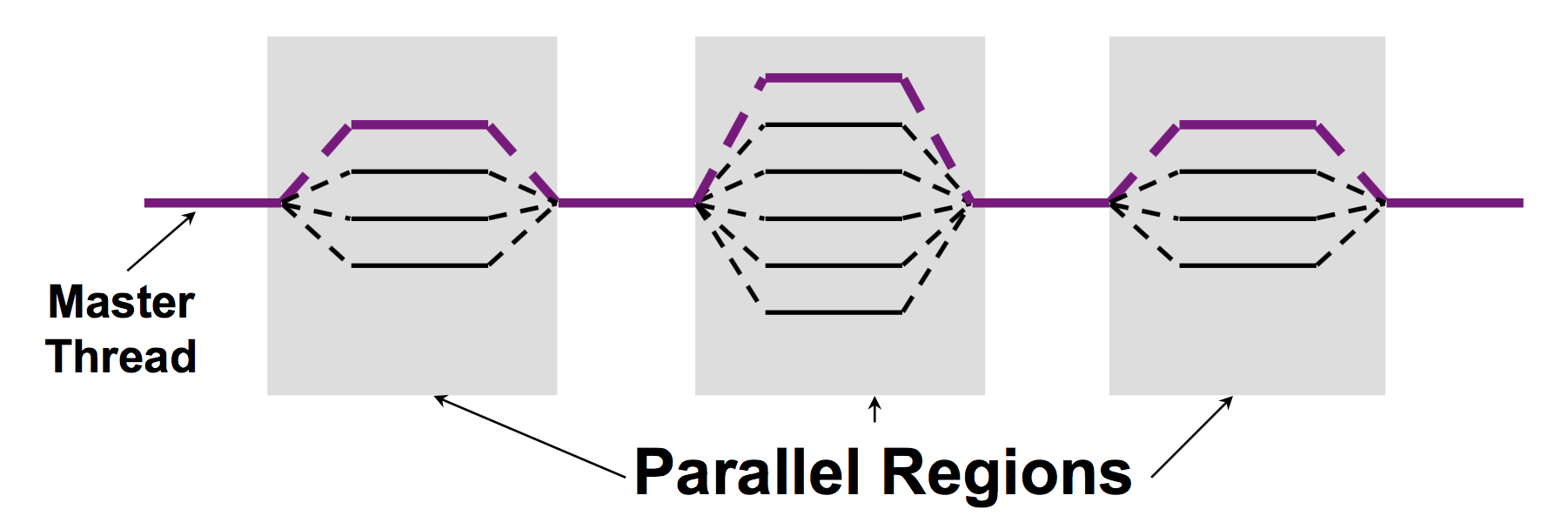
C下的OpenMP
- OpenMP通常运用于并行循环:
- 找出时间花费最多的循环
- 将循环用线程分离
线程间的通信
-
OpenMP是一个共享内存的模型
- 可以通过共享变量通信
-
注意防止竞争条件的出现
- 使用锁保护数据
-
加锁操作的代价很昂贵所以要尽可能改变数据访问形式以减少锁的使用
OpenMP探索
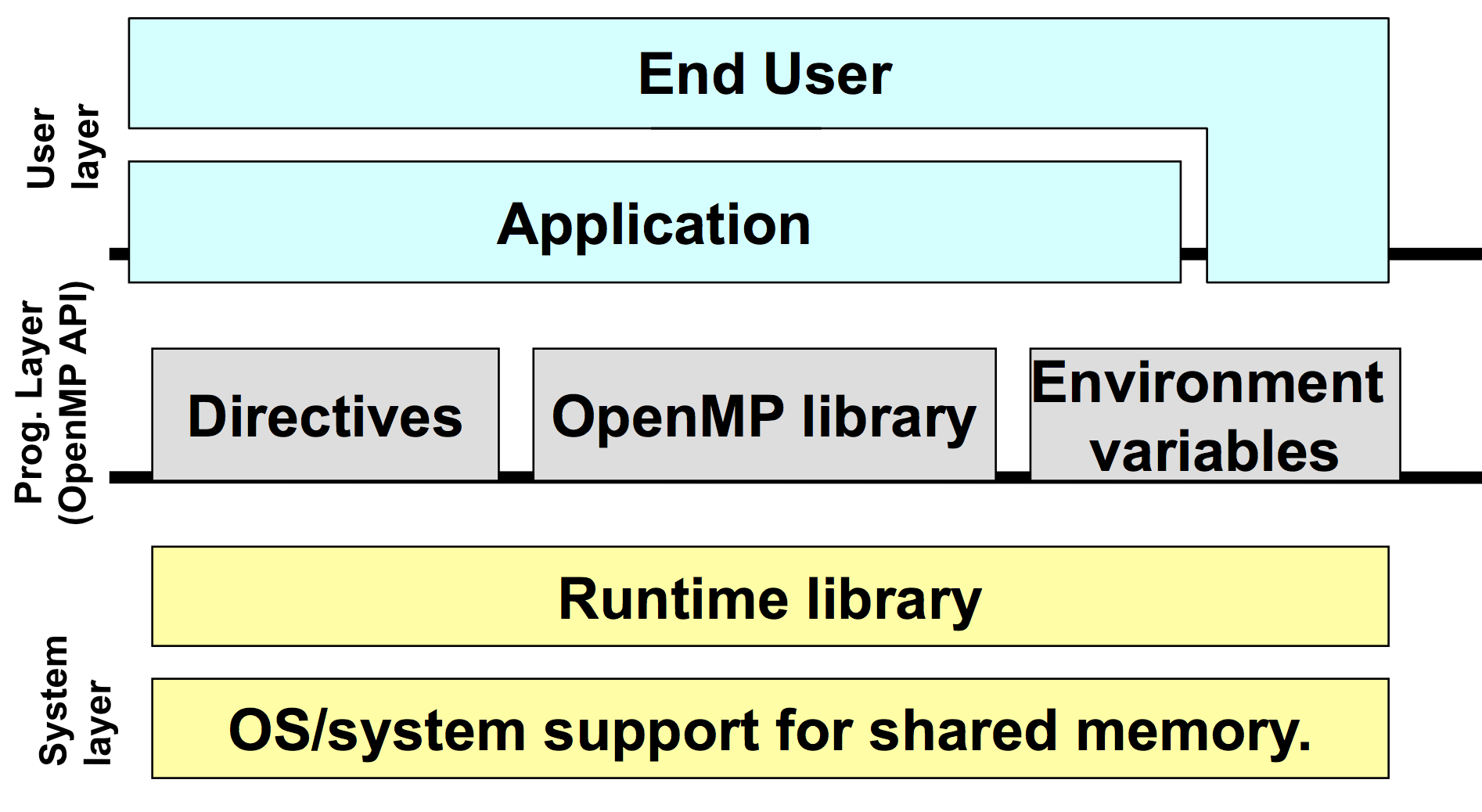
OpenMP在系统中的层次如下图所示:
OpenMP基本用法
- 多数OpenMP结构与结构block共同出现
- 结构block中允许出现exit()(C++)
例:
#pragma omp parallel
{
int id = omp_get_thread_num();
printf("Hello world from %d\n", id);
}
printf("all done\n");
OpenMP组成
OpenMP的组成有5个大类:
- Parallel Regions
- Worksharing
- Data Environment
- Synchronization
- Runtime functions/environment variables
Parallel Regions(并行区域)
对于以下代码:
double A[1000];
omp_set_num_threads(4); //要求openmp将产生确定的线程数
#pragma omp parallel
{
int ID = omp_get_thread_num(); //返回当前线程ID
pooh(ID,A);
}
语句#pragma omp parallel后的block即为并行区域。所有4个线程都将执行block中的代码。其中A被所有4个线程共享
Work-Sharing Constructs
对于以下代码:
#pragma omp parallel
#pragma omp for
{
for (i=0; i < n; i++)
neat_stuff(i);
}
for将循环根据线程分组执行- 在
omp for后默认会有一个同步符号(barrier) - 可以使用
nowait来关闭barrier#pragma omp for nowait- 当有两个连续而且不相关的循环的时候很有用
Work-Sharing Constructs Example
// Sequential code
for(i=0;I<N;i++)
{
a[i] = a[i] + b[i];
}
// Parallel Region
#pragma omp parallel
{
int id, i, Nthrds, istart, iend;
id = omp_get_thread_num();
Nthrds = omp_get_num_threads();
istart = id * N / Nthrds;
iend = (id+1) * N / Nthrds;
for(i=istart;I<iend;i++)
a[i] = a[i] + b[i];
}
// Parallel Region + Work-Sharing
#pragma omp parallel
#pragma omp for schedule(static)
for(i=0;i<N;i++)
a[i] = a[i] + b[i];
schedule子句
- 决定了循环将怎么样映射到线程上去
- schedule(static [,chunk])
- 预先按顺序分好线程,尽量使得每个线程执行的循环数相等(可能相差1因为循环数不一定可以被线程数整除)
- schedule(dynamic [,chunk])
- 实时动态分配任务,哪个线程之前的任务做完就为它分配下一个循环
- 动态分配,但是开销会变高
Data Environment
- 共享内存模型
- 多数变量默认是shared类型的
- 全局变量: 在C里,文件域的变量和static变量是shared类型的
- 通过PRIVATE子句关闭shared
当变量是shared类型时,变量会存在Shared memory中,所有线程会共享改变量,对改变量的修改在其他线程中也可以得到体现。而当变量是private的时候,每个线程会在线程的local存在一个变量,这个变量是各个线程独有的。在一个线程中改变变量并不会改变其他线程中的该变量。
private有一个潜在的问题就是变量必须在block重新赋值,不管变量在block外是否已经初始化过,如下:
void wrong() {
int IS = 0;
#pragma omp parallel for private(IS)
for (j=0; j < 1000; j++)
IS += a[j]; // IS没有初始化
printf(""%d", IS);
}
Synchronization
-
Critical Sections: 一次只有一个线程可以访问critical sections
float res; #pragma omp parallel { float B; int i; #pragma omp for for(i=0;i<niters;i++){ B = big_job(i); // Threads wait their turn – only one at a time calls consume() #pragma omp critical consum (B, RES); } }
-
Atomic: Atomic is a special case of a critical section that can be used for certain simple statements.
#pragma omp parallel private(B) { B = DOIT(I); tmp = big_ugly(); #pragma omp atomic X = X + temp; }
-
Barrier: 所有线程会在此等待直到所有线程到达
-
Ordered: 可以保证每个block按顺序被执行
#pragma omp parallel private (tmp) #pragma omp for ordered for (I=0;I<N;I++){ tmp = NEAT_STUFF(I); #pragma omp ordered res += consum(tmp); }
- Master: Master线程会执行block,其他线程将会跳过此block
Runtime functions/environment variables
Runtime environment routines:
- Modify/Check the number of threads
- omp_set_num_threads(),
- omp_get_num_threads(),
- omp_get_thread_num(),
- omp_get_max_threads()
- omp_set_num_threads(),
- Are we in a parallel region?
- omp_in_parallel()
- How many processors in the system?
- omp_get_num_procs()
Environment Variable
- Control how “omp for schedule(RUNTIME)” loop iterations are scheduled.
- OMP_SCHEDULE “schedule[, chunk_size]”
- Set the default number of threads to use.
- OMP_NUM_THREADS int_literal