并行系统学习之路(三) ---- CUDA学习
NVIDIA CUDA 编程学习
本篇我们来学习CUDA编程,首先我们明确一下几个名词的相互关系:
-
GPU:
- Graphics processing unit
- GPU和CPU一样也是计算机的计算单位,但是他们的设计目标有很大不同,GPU专注于计算,它有有更多的ALU,而CPU为了处理各种计算机指令需要许多其他的复杂结构
- GPU适合大规模并行计算,而CPU适合逻辑控制串行运算
- CPU与GPU架构对比
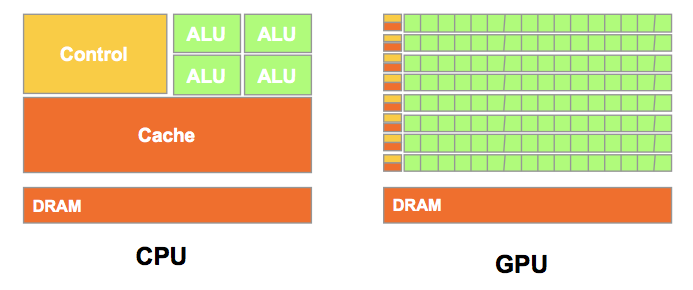
-
GPGPU:
- General Purpose computation using GPU in applications(Other than 3D graphics)
- 通常我们说起GPU,总是会想起3D图形渲染相关的事物,其实我们也可以运用GPU的并行计算特性可以完成很多其他的工作,我们把这种方法称为GPGPU
-
CUDA
- Compute Unified Device Architecture
- CUDA是一个GPU编程模型,相当于一个开发者与GPU之间的接口,开发者使用CUDA可以写出在NVIDIA GPU上运行的并行程序
- CPU称为Host,GPU称为Device
CUDA编程模型
- 相当于CPU的协作处理器
- 拥有自己的DRAM
- SIMD架构
- GPU线程开销小,可以轻松执行多个线程
线程分配
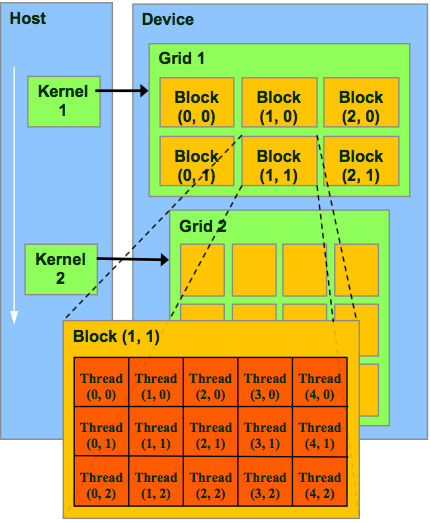
- 每一个Kernel函数将会在包含多个线程block的grid中执行
- 一个block中的所有线程共享memory
- 一个block中的线程可以通过以下方法互相交流
__syncthreads()同步操作- 通过shared memory进行数据分享
- 两个不同block中的线程不能相互交流(除非使用全局memory,但是比较慢)
- 线程和block都有属于自己的ID
CUDA中的三种函数
| 执行地点 | 调用地点 | |
|---|---|---|
__device__ float DeviceFunc() |
device | device |
__global__ void KernelFunc() |
device | host |
__host__ float HostFunc() |
host | host |
CUDA 模型下的内存空间分配
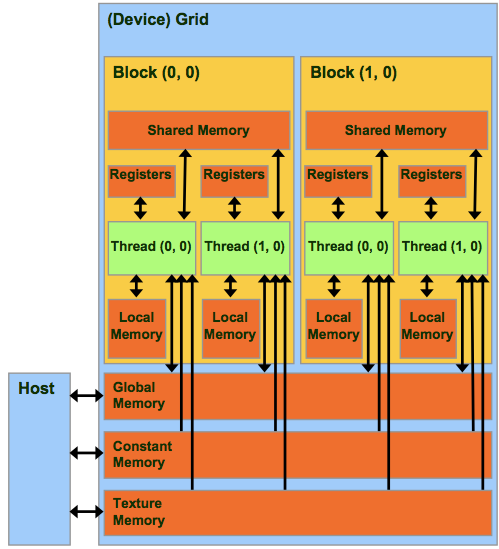
- 每个线程可以
- R/W per-thread registers
- R/W per-thread local memory
- R/W per-block shared memory
- R/W per-grid global memory
- Read only per-grid constant memory
- Read only per-grid texture memory
- host只可以读写global,constant以及texture的memory
- Global memory
- host与device之间读写数据的主要方式
- 所有线程可见,只读
- Texture and Constant Memories
- host初始化的常量
- 所有线程可见,只读
调用Kernel函数实例
调用Kernel函数是必须指定config:
__global__ void KernelFunc(...);
dim3 DimGrid(100, 50); // 5000 thread blocks
dim3 DimBlock(4, 8, 8); // 256 threads per block size_t SharedMemBytes = 64; // 64 bytes of shared memory KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);
- 所有Kernel函数调用都是异步的(除非显式堵塞)
- Kernel函数允许递归
下面是一个实例,该实例把一个数组里的所有值自增了1
__global__ void incrArrayOnDevice(float *a, int N)
{
int idx = blockIdx.x*blockDim.x + threadIdx.x;
if (idx<N) a[idx] = a[idx]+1.f;
}
int main() {
float *a_h, *a_d; int i, N=10;
size_t size = N*sizeof(float);
a_h = (float *)malloc(size);
for (i=0; i<N; i++) a_h[i] = (float)i;
// allocate array on device
cudaMalloc((void **) &a_d, size);
// copy data from host to device
cudaMemcpy(a_d, a_h, sizeof(float)*N, cudaMemcpyHostToDevice);
// do calculation on device:
// Part 1 of 2. Compute execution configuration
int blockSize = 4;
int nBlocks = N/blockSize + (N%blockSize == 0?0:1);
// Part 2 of 2. Call incrementArrayOnDevice kernel
incrArrayOnDevice <<< nBlocks, blockSize >>> (a_d, N);
// Retrieve result from device and store in b_h
cudaMemcpy(a_h, a_d, sizeof(float)*N, cudaMemcpyDeviceToHost);
// cleanup
free(a_h);
cudaFree(a_d);
}
硬件执行模型
- 在grid里,每一个block会被分成warp,每一个warp将由一个多处理器(SM)执行
- device每次只执行一个grid
- 每一个block将由一个多处理器执行
- 因此shared memory空间将位于on-chip shared memory,每个block可以共享
- 一个多处理器可以同时执行多个block
- Shared memory 和寄存器空间是由根据所有同时运行的block来进行分配的
- 因此减少shared memory和寄存器的使用(一个block中的)会增加可以同时运行的block的数量
Thread, Warps, Block 之间关系
- 在一个warp中最多可以有32个线程(小于等于32)
- 一个block中最多有32个warp
- 每个block在一个SM中执行(因此每个warp也一样)
- GF110有16个SMs
- 至少16个block可以保证”填满”device
- 越多效率提升越高
- 如果有足够资源(寄存器,线程空间,Shared memory),一个SM可以执行多个block
总结
- device = GPU = 所有SM
- 多处理器 = 许多处理器和对应shared memory的组合
- Kernel = GPU 程序
- Grid = 一组执行kernel的block
- Block = 一组SIMD的线程,他们可以执行kernel function以及通过shared memory交流
实例 – 使用Leibniz公式求π值
#include <stdio.h>
#include <math.h>
#include "mytime.h"
#define THREADS 512
#define MAX_BLOCKS 64
// find the nearest 2 power
__device__ int NearestPowerOf2 (int n) {
if (!n) return n; //(0 == 2^0)
int x = 1;
while(x < n)
{
x <<= 1;
}
return x;
}
// GPU kernel, we know: THREADS == blockDim.x
__global__ void integrate(int *n, int *blocks, double *gsum) {
const unsigned int bid = blockDim.x * blockIdx.x + threadIdx.x;
const unsigned int tid = threadIdx.x;
double sum;
int i;
int nTotalThreads;
__shared__ double ssum[THREADS];
sum = 0.0;
for (i = bid ; i < *n; i += blockDim.x * *blocks) {
sum += powf(-1, i) / (2*i + 1);
}
ssum[tid] = sum * 4;
// block reduction
__syncthreads();
nTotalThreads = NearestPowerOf2(blockDim.x/2);
for (i = nTotalThreads; i > 0; i >>= 1) { /* per block */
if (tid < i)
if(tid+i < blockDim.x)
ssum[tid] += ssum[tid + i];
__syncthreads();
}
gsum[bid] = ssum[tid];
}
// number of threads must be a power of 2
__global__ static void global_reduce(int *n, int *blocks, double *gsum)
{
__shared__ double ssum[THREADS];
const unsigned int tid = threadIdx.x;
unsigned int i;
int nTotalThreads;
if (tid < *blocks)
ssum[tid] = gsum[tid * THREADS];
else
ssum[tid] = 0.0;
__syncthreads();
nTotalThreads = NearestPowerOf2(blockDim.x/2);
for (i = nTotalThreads; i > 0; i >>= 1) { /* per block */
if (tid < i)
if(tid+i < blockDim.x)
ssum[tid] += ssum[tid + i];
__syncthreads();
}
gsum[tid] = ssum[tid];
}
int main(int argc, char *argv[]) {
int n, blocks;
int *n_d, *blocks_d; // device copy
double PI25DT = 3.141592653589793238462643;
double pi;
double *mypi_d; // device copy of pi
struct timeval startwtime, endwtime, diffwtime;
// Allocate memory on GPU
cudaMalloc( (void **) &n_d, sizeof(int) * 1 );
cudaMalloc( (void **) &blocks_d, sizeof(int) * 1 );
cudaMalloc( (void **) &mypi_d, sizeof(double) * THREADS * MAX_BLOCKS );
while (1) {
printf("Enter the number of intervals: (0 quits) ");fflush(stdout);
scanf("%d",&n);
printf("Enter the number of blocks: (<=%d) ", MAX_BLOCKS);fflush(stdout);
scanf("%d",&blocks);
gettimeofday(&startwtime, NULL);
if (n == 0 || blocks > MAX_BLOCKS)
break;
// copy from CPU to GPU
cudaMemcpy( n_d, &n, sizeof(int) * 1, cudaMemcpyHostToDevice );
cudaMemcpy( blocks_d, &blocks, sizeof(int) * 1, cudaMemcpyHostToDevice );
integrate<<< blocks, THREADS >>>(n_d, blocks_d, mypi_d);
if (blocks > 1)
global_reduce<<< 1, 512 >>>(n_d, blocks_d, mypi_d);
// copy back from GPU to CPU
cudaMemcpy( &pi, mypi_d, sizeof(double) * 1, cudaMemcpyDeviceToHost );
gettimeofday(&endwtime, NULL);
MINUS_UTIME(diffwtime, endwtime, startwtime);
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
printf("wall clock time = %d.%06d\n",
diffwtime.tv_sec, diffwtime.tv_usec);
}
// free GPU memory
cudaFree(n_d);
cudaFree(mypi_d);
return 0;
}